Luga Lee twt企业IT社区
【摘要】基於 VM 環境所部署的 Spring Boot 應用服務,運行過程中內存利用往往達到 90% 甚至以上,本文嘗試對此類在實際業務場景中內存表現的活動現象及背後原因進行分析。
【作者】李傑,專注於Java虛擬機器技術、雲端原生技術領域的探索與研究,個人大眾號「架構驛站」。
在實際的業務場景中,有沒有發現這樣一種場景:基於VM 環境上面所部署的Spring Boot 應用服務,往往在運行過程中將內存利用的足夠“猥瑣”,常常達到90% 甚至以上,此時 ,很大一部分夥伴就開始「叫」了。 曰:領導,記憶不夠了,趕緊擴容! ! ! (此刻,有大佬肯定在想:擴你妹,整天搞這些沒用的~)
那個傻子是不是瘋了? 不知道身為所謂的「技術」人員,大家是如何面對的,如何解決? 本文將聚焦於 Linux 記憶體結構、記憶體分析以及 OOM killer 等 3 個面向以及筆者多年的實務經驗總結來進行解析。
記憶體結構
從宏觀角度而言,記憶體管理系統是作業系統最重要的部分之一。 在記憶體管理的系統呼叫方式,事實上,基於 POSIX 並沒有給記憶體管理指定任何的系統呼叫。 然而,Linux 卻有自己的記憶體系統調用,主要係統調用如下:
系統呼叫 描述
s = brk(addr) 改變資料段大小
a = mmap(addr,len,prot,flags,fd,offset) 進行映射
s = unmap(addr,len) 取消映射
1、brk 透過給出超過資料段之外的第一個位元組位址來指定資料段的大小。 如果新的值要比原來的大,那麼資料區就會變得越來越大,反之會越來越小。
2、mmap 和 unmap 系統呼叫會控制映射檔。 mmp 的第一個參數 addr 決定了檔案對映的位址。 它必須是頁面大小的倍數。 如果參數是 0,系統會指派位址並傳回 a。 第二個參數是長度,它告訴了需要映射多少位元組。 它也是頁面大小的倍數。 prot 決定了映射檔的保護位,保護位可以標記為 可讀、可寫、可執行或這些的結合。 第四個參數 flags 能夠控製檔案是私有的還是可讀的以及 addr 是必須的還是只是進行提示。 第五個參數 fd 是要對應的檔案描述子。 只有開啟的檔案是可以被映射的,因此如果想要進行檔案映射,必須開啟檔案;最後一個參數 offset 會指示檔案從何時開始,不一定每次都要從零開始。
針對 Linux 記憶體管理及實現,其實其涉及的面較廣,較為複雜,從電腦早期開始,我們在實際的業務場景中所使用的記憶體往往都要比系統中實際存在的記憶體多。 為此,記憶體分配策略克服了這個限制,而其中最有名的就是引入: 虛擬記憶體(Virtual Memory)。 透過在多個競爭的進程之間共享虛擬內存,虛擬內存得以讓系統有更多的內存,以方便維護系統資源的分配。 先來張總概覽圖,具體如下圖所示:
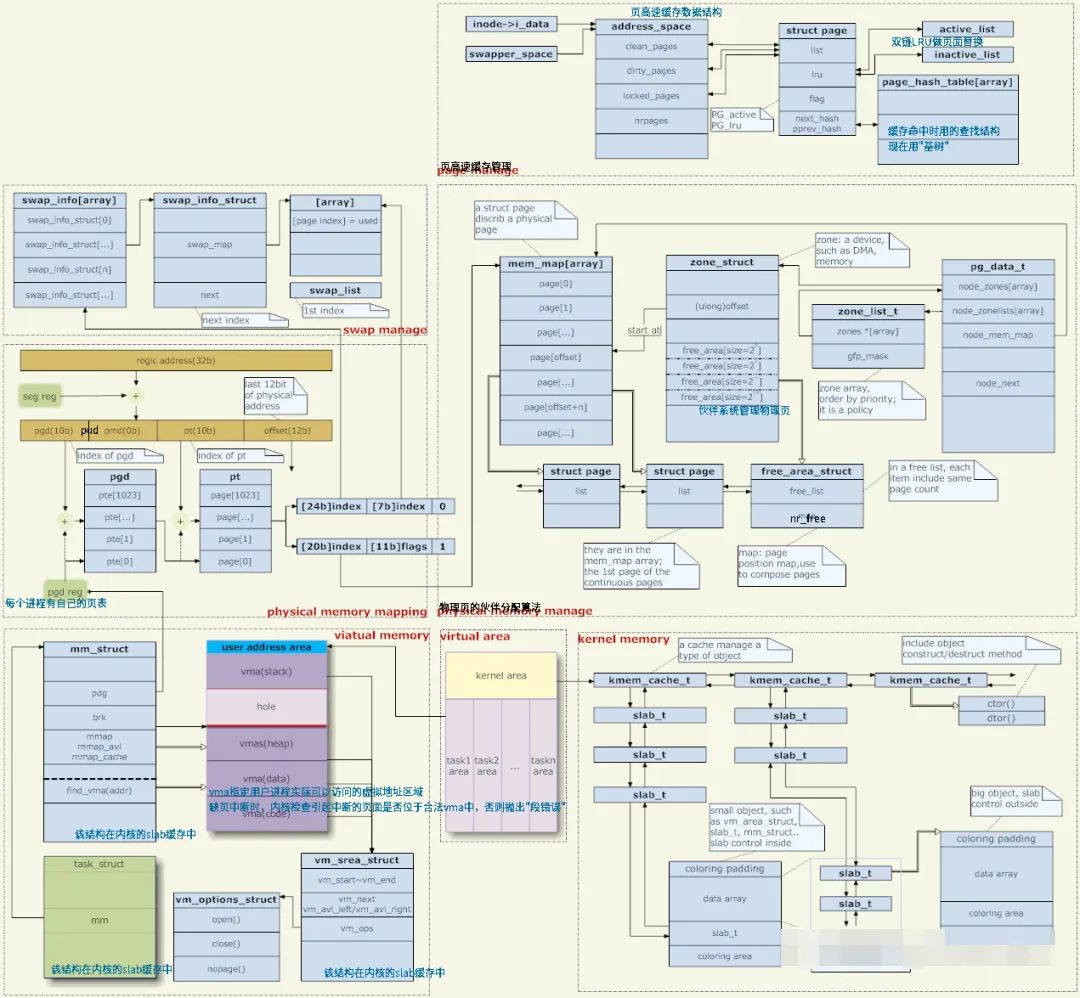
Linux 內存,通常被認為指的是“物理內存”,然而,只有內核才可以直接訪問物理內存,進程需要訪問內存,Linux 內核則需要為每個進程提供一個獨立的虛擬地址空間,訪問的是 虛擬記憶體。
通常而言,虛擬記憶體空間的內部被劃分為核心空間和使用者空間:
1.進程在用戶態,只能存取用戶空間內存
2.行程進入內核態才能存取核心空間內存
3.每個行程都包含內核空間,但這些內核空間都關聯相同的實體內存
而針對記憶體映射,其主要將虛擬記憶體位址映射到實體記憶體位址,為了完成記憶體映射。 核心每個進程都維護了一張頁表,記錄虛擬位址和實體位址的映射關係,頁表實際儲存在CPU 的記憶體管理單元 MMU,這樣處理器就可以直接透過硬體找出要存取的記憶體。
再來一張內核線形位址空間佈局圖,具體可參考如下「硬核」示意圖:
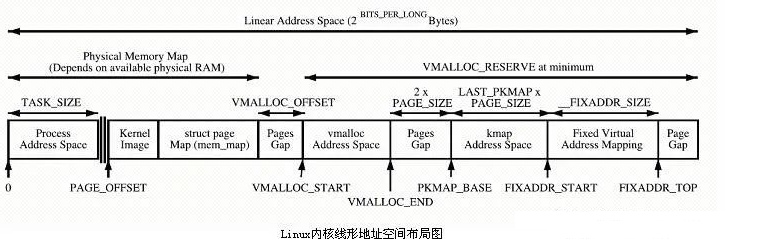
針對上述結構圖,簡單描述如下:
1.核心直接映射空間 PAGE_OFFSET~VMALLOC_START,kmalloc和__get_free_page()分配的是這裡的頁面。 二者是藉助 Slab分配器,直接分配實體頁再轉換為邏輯位址(實體位址連續)。 適合分配小段記憶體。 此區域 包含了核心鏡像、實體頁框表mem_map 等資源。
2.核心動態映射空間 VMALLOC_START~VMALLOC_END,被 vmalloc 用到,可表示的空間大。
3.核心永久映射空間 PKMAP_BASE ~ FIXADDR_START,kmap
4.核心臨時映射空間 FIXADDR_START~FIXADDR_TOP,kmap_atomic
記憶體分析
針對記憶體分析部分,其實可利用的手段或策略較多,基於不同段位的水平高低之分,通常,我們可以藉助Top、Free 指令以及Vmstat 指令進行追蹤及觀測記憶體的動態活動變化趨勢,以即時了解 目前作業系統的資源水位,具體如下所示:
[administrator@JavaLangOutOfMemory ~ ] %top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 128032 7996 5556 S 80.0 80.4 0:01.03 java
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
基於上述輸出結果,簡單解析如下:
1、VIRI: 虛擬內存,包括了進程的代碼段、數據段、共享內存、已經申請的堆內存和已經換出的內存等,已經申請的內存,即使還未分配物理內存,也算做虛擬內存
2、RSS: 常駐內存,是進程實際使用的實體內存,不包括 Swap 和共享內存
3、SHR: 共享內存,包括與其他進程共同使用的真實共享內存,包括加載的動態鏈接庫以及程序的代碼段
4、%MEM: 進程使用實體記憶體佔系統記憶體的百分比
[administrator@JavaLangOutOfMemory ~ ] %free
total used free shared buff/cache available
Mem: 2031744 98176 1826192 8784 107376 1800144
Swap: 2097148 0 2097148
此命令列輸出內容較為簡單:主要列印已使用、剩餘、可用、共享記憶體以及快取等資訊。 部分參數釋義如下圖所示:
1、Shared: 共享記憶體, 共享記憶體是透過 Tmpfs 實現的,它的大小就是 Tmpfs 使用的記憶體大小。
2、Available: 可用內存,是新進程可以使用的最大內存,包括剩餘內存和還未使用的內存。
3、Buffer/Cache: 快取包括兩部分,一部分是磁碟讀取檔案的頁緩存,用來緩存從磁碟讀取的數據,加速以後再次存取速度,另一部分是Slab 分配的可回收快取;緩衝區是 對原始磁碟的暫存,用來快取將要寫入磁碟的數據,統一最佳化磁碟寫入。
[administrator@JavaLangOutOfMemory ~ ] %vmstat 1 1
procs ———–memory———- —swap– —–io—- -system– ——cpu—–
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1815348 2108 111872 0 0 1 0 11 11 0 0 100 0 0
基於上述輸出結果,簡單解析如下:
1、si: 換入,每秒從磁碟讀入虛擬記憶體的大小,若此值長時間持續大於0,表示實體記憶體不夠或記憶體洩漏,需要定位問題。
2、so: 換出,每秒鐘從記憶體寫入磁碟的大小,若此值長時間持續大於0,表示實體記憶體不夠用,就需要排查記憶體問題。
OOM Killer
通常有這樣的一種場景:若一台VM (虛擬機)上部署多個應用服務,此處,暫以Spring Boot 微服務為例,在某種特殊的時刻,例如:業務促銷、壓力測試或 當某一個聯機負載節點或因網路抖動而掛掉時,此台VM 上的服務突然在毫無徵兆的情況下,突然被「掛掉」。
同時,我們開始蒐集相關線索,以便能夠快速定位到問題原因,將「罪魁禍首」逮捕歸案。
那麼,為什麼會出現這種問題呢? 它是如何產生的? OOM,全稱為 “Out Of Memory”,即 記憶體溢位。 OOM Killer 是 Linux 自我保護的方式,防止記憶體不足時出現嚴重問題。
Linux 核心所採用的此種機制會不時監控所運行中佔用記憶體過大的進程,尤其針對在某一種瞬間場景下佔用記憶體較快的進程,為了防止作業系統記憶體耗盡而不得不自動將此 進程Kill 掉。 通常,系統核心偵測到系統記憶體不足時,篩選並終止某個行程的過程可以參考核心原始碼:linux/mm/oom_kill.c,當系統記憶體不足的時候,out_of_memory()被觸發,然後呼叫select_bad_process( ) 選擇一個”bad” 進程殺掉。 如何判斷和選擇一個」bad 進程呢?Linux 作業系統選擇」bad」進程是透過呼叫 oom_badness(),挑選的演算法和想法都很簡單很樸實:最 bad 的那個進程就是那個最佔用記憶體的進程。
OOM Killer 原始碼解析
OOM killer的核心函數是 out_of_memory(), 執行流程如下:
1.呼叫 check_panic_on_oom() 檢查是否允許執行核心恐慌,假如允許,需要重新啟動系統。
2.若定義了 /proc/sys/vm/oom_kill_allocating_task 即允許 Kill 掉目前正在申請分配物理記憶體的程序,那麼殺死目前程序。
3.呼叫 select_bad_process,選擇 badness score 最高的進程。
4、呼叫 oom_kill_process, 殺死選擇的進程。
我們透過分析 Badness Score 的計算函數來理解 OOM Killer 是如何選擇需要被 Kill 掉的進程,具體原始碼可參考如下所示:
unsigned long oom_badness(struct task_struct *p, struct mem_cgroup *memcg,
const nodemask_t *nodemask, unsigned long totalpages)
{
long points;
long adj;
/* 假如该进程不能被kill, 则分数返回0. */
if (oom_unkillable_task(p, memcg, nodemask))
return 0;
p = find_lock_task_mm(p);
if (!p)
return 0;
/* 获取该进程的 oom_score_adj, 这个是用户为进程设置的 badness score
* 调整值,假如这个值为-1000或者进程被标记为不可被kill,或者进程处于
* vfork()过程,badness score返回0. */
adj = (long)p->signal->oom_score_adj;
if (adj == OOM_SCORE_ADJ_MIN ||
test_bit(MMF_OOM_SKIP, &p->mm->flags) ||
in_vfork(p)) {
task_unlock(p);
return 0;
}
/* badness score分数 = 物理内存页数 + 交换区页数 + 页表Page Table数量. */
points = get_mm_rss(p->mm) + get_mm_counter(p->mm, MM_SWAPENTS) +
mm_pgtables_bytes(p->mm) / PAGE_SIZE;
task_unlock(p);
/* 利用以下公式对 badness score 值进行调整. */
adj *= totalpages / 1000;
points += adj;
/* 返回 badness score, 假如等于0, 则返回 1. */
return points > 0 ? points : 1;
}
透過對 Badness Score 計算函數的分析,我們可以發現 OOM Killer 是基於 RSS 即常駐的實體記憶體來選擇進程進行 Kill 操作, 從而釋放相關記憶體以進行系統自我保護。 有關 OOM Killer 相關配置、查看及分析將於後續文章給出,大家到時留意查看。
綜上所述,本篇文章主要透過基於對Linux 記憶體結構、分析及OOM Killer 3個核心維度,從主動及被動場景等2 面向對Linux 作業系統記憶體的剖析,以探討在實際的業務場景中, 記憶體表現的相關活動及經驗認知。