技術丨思科的 NVMe-oF 的部署錦囊都在這裡了
思科聯天下
今天就來看看如何選擇合適的 NVMe-oF 技術,以及思科的解決方案和不同金融情境下的建議。
對於計劃升級基礎設施以支援 NVMe-oF 的金融業 IT 架構師來說,主要問題是採用何種技術架構。 自然,答案將取決於他們當前基礎設施的內容,以及他們對未來的計劃和預算。
另一個關鍵因素是時機。 NVMe/RoCEv2 目前顯示出潛力,但在準備好可靠地承擔企業級關鍵工作負載之前,它可能還需要幾年的時間來發展。 當技術成熟時,NVMe/TCP 看起來也可能提供出色的性價比,但這同樣需要幾年的時間。
目前,大多數 IT 架構師得出結論,FC 為企業關鍵任務工作負載提供了最成熟的資料傳輸協議,使 NVMe/FC 成為正確的儲存網路架構選項。
複雜的協定棧不是儲存的最佳選擇
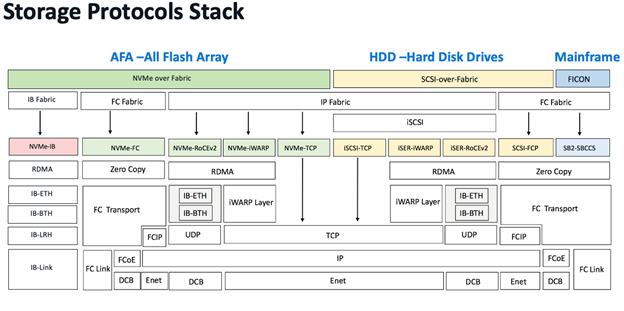
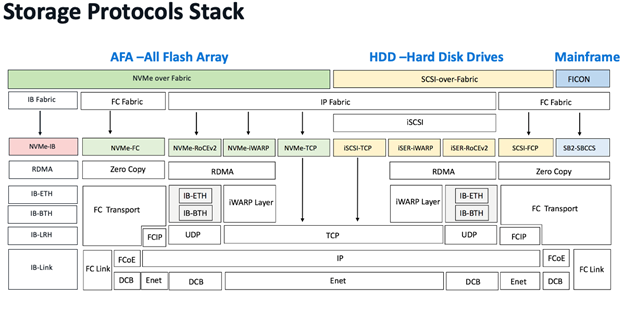
NVMe 協定比 SCSI 協定更有效的原因之一是 NVMe 的協定堆疊明顯更簡單。 協定堆疊的簡化性也非常重要,因此我們可以比較不同的 NVMe 結構的協定堆疊。 光纖通道、RoCEv2 和 TCP 的堆疊在下面的儲存 Fabric 協定全棧圖中可以看到差異。
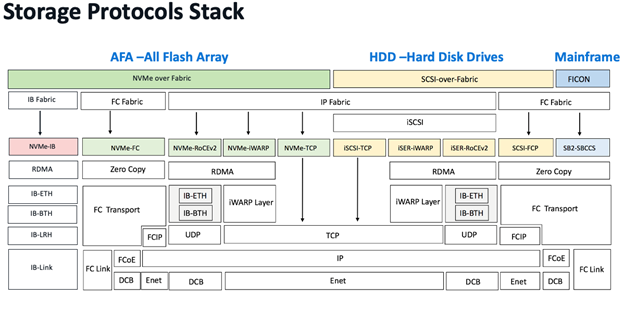
IP/乙太網路相對於光纖通道的複雜性是顯而易見的。 協定中有幾個關鍵問題導致了這種複雜性:乙太網路和 IP(以及 TCP/UDP)在比光纖通道 FC 更獨立的層中實現傳輸管道。 IP 網路的設計初衷是必須支援具有數十億個節點的全球範圍位址分配和路由,需要多個複雜的層面和演算法支援。 光纖通道 FC 是為資料中心規模設計的,有其自身的複雜性,但比 IP 的全球規模要簡單得多。
乙太網路是在網路早期作為一種最佳共享介質開發的。 該協議演變了多種用於避免環路、快速地址學習等的零碎機制。 多年來,流量控制逐漸加強。 相較之下,光纖通道的開發人員能夠從這些早期的經驗教訓中吸取教訓,從而創建一個整體上更一致的協定。
對協定棧的要求。 光纖通道一直專注於高級資料中心用例,因此沒有朝向更大的規模發展。
在這裡承認TCP 和RoCEv2 堆疊的複雜性並不一定會增加微不足道的延遲;許多堆疊複雜性由啟用RDMA 的專用NIC 或TCP offload 在「硬體」 中處理(儘管通常涉及基於ASIC 的處理器核心)引擎 。 但複雜的堆疊在實際部署中會轉化為配置管理、互通性、故障排除與分析等多方面的挑戰。
IP/乙太網路複雜性的遺留問題代表了優質、無損環境中的挑戰:設備的預設行為以及支援人員的經驗和培訓主要面向主流市場。 雖然應該可以利用一些高級操作來配置乙太網路和 IP 設備,但這種操作不是正常的預設設置,通常也不是網路維運中不同角色的能力所及。 相較之下,光纖通道始終被設計為簡單的高可用網絡,這在 NVMe 環境中和幾十年來在 SCSI 環境中一樣都是如此。
新堆疊建立新的安全目標
在光纖通道 SAN 中維護高價值儲存資產的優勢之一是此類結構難以透過 IP 網路存取。 從 IP 協定到穩定的光纖通道協定棧,根本沒有路徑。 攻擊者無法透過 IP 發送光纖通道訊框來探測 SAN。 因此,經常出現的小安全漏洞不會轉換為儲存卷的零日漏洞。 複雜且相對未經驗證的 RoCEv2 和 TCP 堆疊開闢了新的威脅面,這些威脅面相對可透過 IP 訪問,從而增加了整個組織 IP 網路中安全機制管理的複雜性。
企業儲存架構遷移的考慮
NVMe over Fibre Channel 提供光纖通道傳輸的效能和穩健性,以及在同一基礎架構上同時運作 FCP 和 FC‑NVMe 協定的能力。 這種雙協定方法使 IT組織能夠將其儲存磁碟區從 SCSI 順利過渡到 NVMe,有了 NVMe over Fibre Channel,當組織開始採用 NVMe 時,無需推倒和取代 SAN,也無需創建昂貴的新基礎設施。 雙協定 HBA 和驅動程式堆疊意味著每個儲存應用程式都可以根據需要逐步遷移。 SCSI 資產可以逐卷從 SCSI 遷移到 NVMe。 低風險的效能敏感磁碟區可以先遷移,風險敏感的捲可以保留到以後。 此外,可以在頂級企業陣列上建立和維護關鍵資產的主副本,同時可以將營運副本發佈到相同 SAN 中的低成本陣列,以供其他應用程式使用。
金融業應用可以透過多種方式受益於 NVMe 技術。 所以,建議路線圖應該適用於多種 NVMe 解決方案實施。
決定部署哪種類型的NVMe over Fabrics 協定取決於應用,您的資料中心技術設施能力以及這些應用程式對NVMe over RoCE、NVMe over FC 或NVMe over TCP的準備情況,完善的解決方案將支援所有這些協定 ,
思科針對 NVMe-oF 部署的建議
建議NVMe/FC 協定和SCSI/FC 協定使用相同的光纖通道基礎設施,並使用不同的VSAN 來保持NVMe 和SCSI FC 流量之間的分離, NVMe/FC 提供更高的效能和更好的錯誤復原( SLER),目前光纖通道速度為64G,128G 標準正在研究中。
整體的方案示意如下:
Cisco MDS 提供豐富的基於ASIC 的NVMe/FC 分析功能,以及用於進一步分析NVMe 幀的專用附加NPU,目前基於以太網技術的NVMe over ROCEv2 和NVMe over TCP 還沒有基於晶片級別的可以分析NVMe 幀的 能力。
思科的 MDS SAN 解決方案能提供對 NVMe/FC 完整的支援
這是客戶在涉及 SAN 的對話中最常見且最關心的問題。 Cisco MDS SAN 完全支援 NVMe。
•透明支援 —— 無需額外的硬體/指令
•可與任何目前使用 Cisco NX-OS 8.x 版本的 16G/32G 交換矩陣交換器或目前 Cisco MDS 9700 16G/32G 模組搭配使用
•無需額外許可證
•無需額外功能即可識別 NVMe 指令
針對 NVMe 的整體部署方案,思科提出了 NVMe-Anywhere 整體解決方案
此方案建議通常 NVMe/RoCEv2 使用無損乙太網路部署在機架內, 流量工程透過 DSCP、PFC、ECN、DCQCN、IB/CNP 功能進行管理,以發揮 NVMe/RoCEv2 的最佳效能。 對 NVMe/RoCEv2 進行故障排除需要了解 Infiniband TH 協定。 NVMe/RoCEv2 不能用於長距離(NVMe/TCP 是更好的選擇),因此在一部分場合可以部署 NVMe/TCP 解決方案。 採用思科的N9K 解決方案實現NVMe/RoCEv2和NVMe/TCP的同時,N9K支援FC/FCoE 的特性,配合思科MDS 交換器可以實現全端全連通的NVMe over Fabric 資料中心解決方案,實現真正的NVMe-Anywhere 才是客戶現實環境的最佳選擇,同時相容於現有SAN 環境,實現無縫遷移,多層存儲,新舊設備共存,充分體現投資保護。
在思科 NVMe-Anywhere 整體解決方案下,思科提出針對 NVME-oF 的選擇建議:
•將企業級關鍵任務應用程式部署在 NVMe/FC 光纖通道環境中;
• 關鍵業務的儲存遷移可以在統一的 FC 結構上直接進行,從 SCSI 遷移到 NVMe/FC;
• 對於某些考慮較低成本或較長距離需求的 NVMe 儲存資料流量,可以使用 NVMe/TCP ;
• 針對 cloud native 相容的部分應用場景,可以考慮採用 NVMe/RoCEv2 作為 DAS 替代,目前狀態下流量應盡可能限制在機架層級(低於 TOR 交換器);
• 儲存網路要具備 NVMe 流量的可視分析能力;
• 透過統一的融合管理平台管理混合結構 (Ethernet/FC) 。
綜上,在目前的階段下,針對金融業的應用特點,大部分使用情境以確保關鍵業務的可靠性和安全性為首要目標。 因此,選擇成熟、穩定、安全的 NVMe/FC 技術作為關鍵業務場景的首選,對於非關鍵業務場景可以考慮其他類型的 NVMe-oF 技術。 思科公司憑藉完備的產品線和經驗豐富的技術支援能力,可以幫助金融業客戶採用 NVMe 技術支援各種類型的應用,實現 NVMe-Anywhere。