原創 網絡技術乾貨圈
如果只管一台伺服器,很多事情都很好辦。
系統出了問題,連上去看一下;磁碟快滿了,手動清一清;服務掛了,重啟一下,基本上就能頂住。
但一旦伺服器數量變成100台,事情就完全不是量級了。
這時候最容易發生的,不是“技術不夠”,而是“管理方式還停留在單機思維”。
你會發現,伺服器越多,重複工作越多;伺服器越多,配置越容易亂;伺服器越多,出問題後排查越像在找針。
所以,真正會管理100台伺服器的人,拼的不是熬夜能力,而是體系化思維。
核心就一句話:把伺服器當成隊伍來管,而不是一堆零散的機器來修。
第一步:先別急著上工具,先把「家底」摸清很多人一上來就想部署監控、自動化、告警平台,結果最後發現,伺服器到底有多少台、分別跑了什麼業務、誰負責、在哪個機房,自己都說不全。
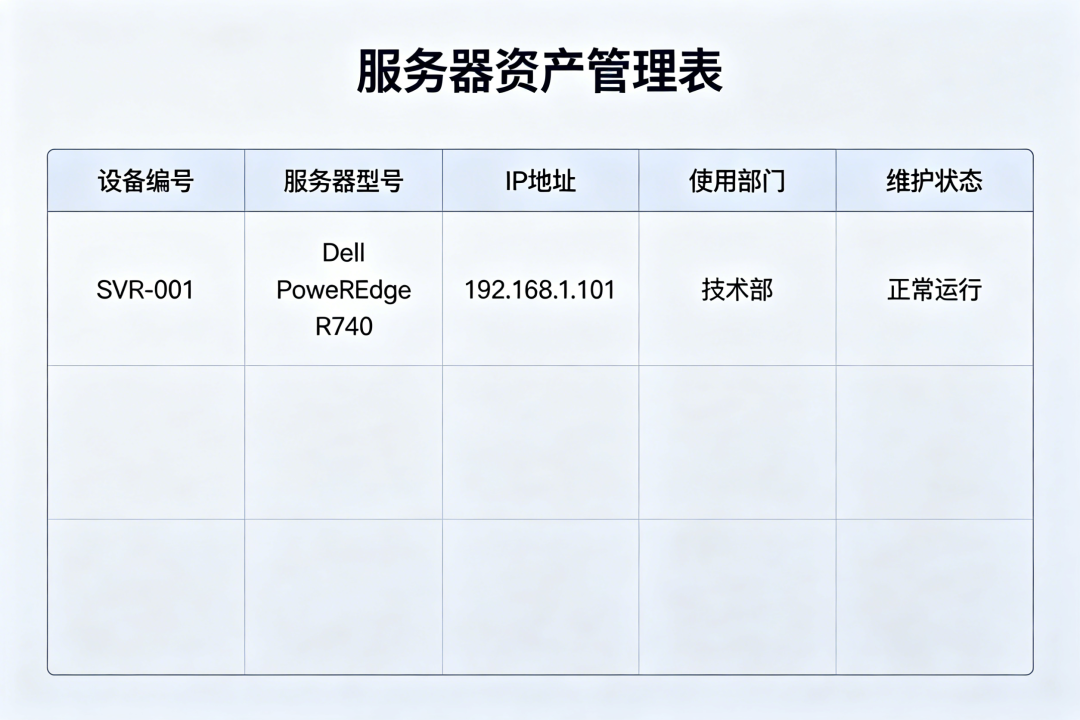
這一步最重要:先建立資產台帳。
100台伺服器裡,至少要弄清楚這些資訊:主機名稱、IP位址、機房位置、作業系統版本、用途、負責人、業務歸屬、上線時間、保固狀態、重要等級。
這些資訊看起來很基礎,但到了真正排障、擴容、遷移、巡檢的時候,全靠它們撐著。我建議把這套台帳做成一個統一的資產表,即使前期用表格也行,但必須保持唯一來源。不要這邊一份Excel,那邊一份文檔,最後誰都不知道哪個是準的。
如果條件允許,最好往CMDB方向走,讓資產、應用、負責人、警告、變更都能串起來。這樣以後不是“找機器”,而是“找關係”。
第二步,統一標準,不要讓每台伺服器都長得不一樣
伺服器一多,最怕的就是「各裝各的,各配各的,各改各的」。
今天這台開了SSH密碼登錄,明天那台關閉了防火牆,後天某台機器的時區、日誌路徑、核心參數又不一樣。
時間一長,管理難度會倍增。
所以,100台伺服器必須有統一標準。

系統版本盡量統一,常用軟體版本盡量統一,目錄結構盡量統一,日誌路徑盡量統一,命名規則也盡量統一。
例如:
主機名稱依業務+環境+編號命名
登入方式統一用金鑰或統一認證
系統初始化腳本統一
執行時間同步統一走同一個NTP來源
日誌擷取統一存取同一個平台
標準化的好處很直接:新機器上線快,排查問題快,交接成本低,出故障時也不容易亂。對100台伺服器來說,統一標準不是“追求整齊”,而是“減少管理成本”。
第三步,監控一定要先做,不然問題都是事後發現
伺服器管理最害怕的狀況之一,就是業務已經掛了,大家才知道。
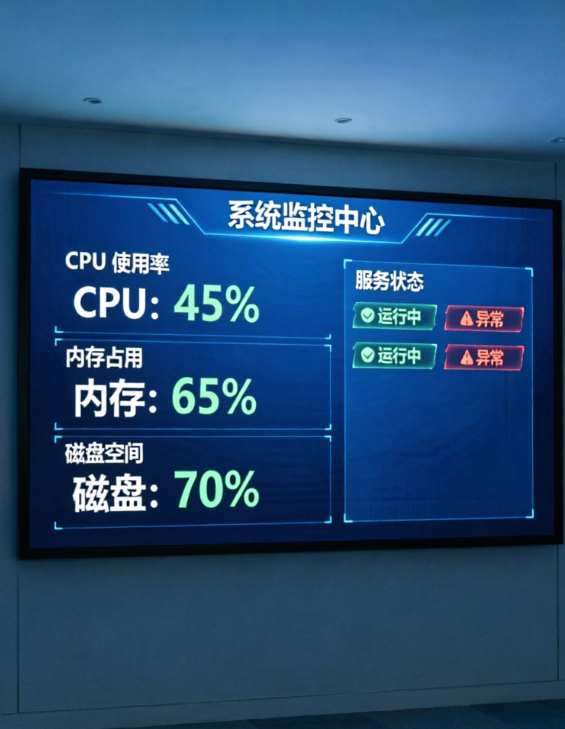
所以監控必須提前鋪好,而且不是只看“在線不在線”,而是要看真正影響業務的關鍵指標。
至少要盯住這些:CPU 使用率、記憶體佔用、磁碟空間、磁碟 I/O、網路流量、連接埠狀態、進程存活、服務回應時間、系統負載。
如果是資料庫、快取、Web、中間件,還要繼續細分到連線數、慢查詢、佇列堆積、QPS、錯誤率、同步延遲等。
監控體系最好分三層:
第一層是主機監控,關注伺服器本身健康狀況;
第二層是服務監控,關注關鍵進程和介面是否正常;第三層是業務監控,關注用戶是否真的能正常使用。
很多團隊只盯主機,結果機器明明活著,業務已經卡死了。
所以,監控不是看機器亮不亮燈,而是看業務順不順。
]告警也要講方法。
別把所有閾值都設得很敏感,不然一天幾百條告警,最後大家都會麻木。
告警要分級,緊急告警直接通知值班人員,普通告警進工單或日報,趨勢告警用來做容量規劃。
第四步:自動化不是選項,而是必選項
如果還在用人工一台一台裝軟體、改設定、發腳本,規模一上來幾乎必出問題。
自動化的價值,不只是省時間,而是:
消除「人為差異」
常見自動化場景包括:
- 批量初始化系統
- 批量建立與下發帳號
- 批量修改配置
- 批量部署服務
- 批量收集日誌
- 批量打補丁
- 批量巡檢
工具方面可以使用:
- Ansible
- SaltStack
- Puppet
即使不使用完整的配置管理平台,也至少要做到:
所有重複操作腳本化、流程化
更進一步,建議將腳本納入 Git 管理:
- 可追蹤修改歷史
- 可回溯誰改了什麼
- 可說明為什麼修改
當人力緊張、機器量大、時間窗口短時,自動化是唯一維持穩定節奏的方法。
第五步:權限管理必須收緊
伺服器越多,權限風險越高。
很多事故其實不是系統壞掉,而是:
- 人員誤改配置
- 臨時開放高權限帳號
- 測試命令遺留在線上環境
建議做法:
- 使用堡壘機 / 跳板機統一登入
- 採用最小權限原則
- 高權限操作需審批
- 帳號需明確歸屬
- 離職 / 轉崗 / 協作即時回收權限
同時一定要建立操作審計:
- 誰在什麼時間登入
- 執行了哪些命令
- 修改了哪些系統
這些紀錄在故障時就是關鍵證據。
一句話總結:
沒有審計的100台伺服器,就像有100個門卻只裝了一把鎖。
第六步:補丁與升級不能拖
典型現象是:
- 沒事時:先別動
- 出漏洞時:緊急修
正確方式應該是「常態化更新」。
包括:
- 核心系統補丁
- 安全更新
- Web 元件升級
- 資料庫小版本更新
推薦流程:
- 先在測試環境驗證
- 小規模灰度發布
- 再逐步擴大到全量
最忌諱:
一次性全量升級
建議分批進行:
- 低風險業務優先
- 核心系統最後更新
補丁管理的核心不是快,而是穩。
第七步:備份要做,恢復更要測
很多團隊的問題是:
「我們有備份」≠「我們能恢復」
真正的備份應該包含:
- 資料庫
- 配置文件
- 憑證與金鑰
- 業務數據
- 系統快照
策略上要分層:
- 熱數據:高頻備份
- 冷數據:低頻備份
- 核心系統:異地備份 + 災備
更重要的是:
定期做恢復演練
因為很多事故不是沒備份,而是:
- 步驟不完整
- 權限不足
- 版本不相容
備份的價值,在於「恢復那一刻」。
第八步:日誌必須集中管理
100台伺服器如果逐台查 log,效率會非常低。
正確方式是建立集中式日誌平台:
統一收集:
- 系統日誌
- 應用日誌
- 存取日誌
- 錯誤日誌
集中後的好處:
- 可按時間搜尋
- 可按主機過濾
- 可按關鍵字分析
- 可關聯多節點問題
尤其在:
- 間歇性故障
- 複雜鏈路問題
- 高併發異常
集中日誌是排障效率的關鍵。
此外,日誌還有:
審計與追溯價值
第九步:變更必須可控
伺服器數量越多,變更風險越高。
常見問題:
- 改配置
- 發版本
- 換證書
- 調參數
看似小變更,累積起來就是大風險。
必須建立變更流程:
- 變更前:影響評估
- 變更時:明確責任人
- 變更後:驗證結果
- 失敗時:可回滾
核心原則:
所有生產環境操作都必須當成正式變更處理
成熟團隊的標誌不是「不出變更」,而是:
- 可追蹤
- 可回滾
- 可復盤
第十步:容量規劃要前置,而不是救火
很多問題本質不是故障,而是:
沒有做容量規劃
例如:
- 磁碟滿:沒有趨勢監控
- CPU 高:負載預估錯誤
- 網路卡:沒有峰值預留
- DB 慢:連線數設計不足
應該持續觀察:
- 資源使用趨勢
- 峰值 vs 平均值
- 業務成長速度
- 高峰期波動
透過這些數據:
提前做擴容,而不是事後補救
容量規劃的價值在於:
用預測換掉緊急處理
結語:100台伺服器的本質是「系統能力」
如果我要管理100台伺服器,我會優先做這幾件事:
- 先摸清資產與環境
- 再統一標準與流程
- 建立完整監控與告警
- 推進自動化
- 收緊權限與審計
- 做好備份與恢復演練
- 管住變更流程
- 最後才是容量規劃
管理100台伺服器,從來不是比誰更會修機器,也不是比誰更能熬夜。
而是比:
誰能建立一套可以長期運轉的穩定系統。
當系統、流程、工具與規範真正串起來之後,伺服器越多,反而會越穩定。
因為真正成熟的運維不是天天救火,而是:
讓火盡可能不要發生。